在建構好ML機器學習模型之後,接下來,就會遇到一個很大的課題。
要如何改善準確率?
準確率又和那些因素有關?
因為真正的實務上商務應用和工業應用,
只抓取一大堆訓練資料,
直接丟進去ML model裡面train好就可以達到實際應用上所需的要求是很困難的。
例如,很可能會有誤判的情況,誤判又可以直觀的分為兩種。
型一錯誤(Type 1 Error)與型二錯誤(Type 2 Error)。
在這之前,先回頭複習一下統計分類裡面常見的預測結果分類圖
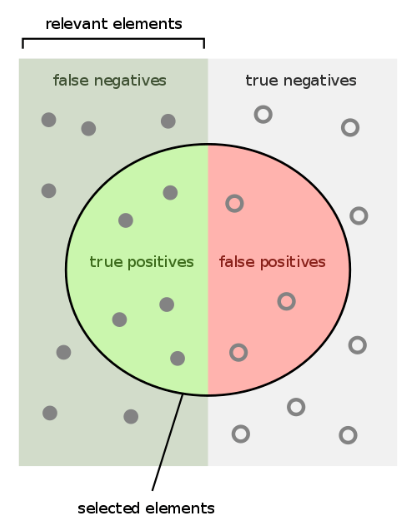
先假定一個題目:
我們所建立的ML機器學習模型所要判別的是,從圖片裡面(預測)辨別出,這圖片裡面是不是有貓咪。
那麼,對這個題目而言,
正確預測的兩種情況就是:
TP: True Positive,實際上圖片裡面有貓咪,而且ML模型也判定有貓咪。
(統計或醫學上常稱為真陽性)
TN: Ture Negative,實際上圖片裡面沒有貓咪,而且ML模型判定沒有貓咪。
(統計或醫學上常稱為真陰性)
依此類推,誤判的兩種情況則是:
FP: False Positive,實際上圖片裡面沒有貓咪,但是ML模型誤判成有貓咪。
(統計或醫學上常稱為偽陽性)
又稱為Type 1 Error。
FN: False Negative,實際上圖片裡面有貓咪,但是ML模型誤判成沒有貓咪。
(統計或醫學上常稱為偽陰性)
又稱為Type 2 Error。
假如能完美的壓低這兩種的誤差固然很好,但是實務上則不然,魚與熊掌不可兼得。
當我們把門檻(threshold)或是特徵(feature)取得更嚴格,
很自然False Positive會降低(因為能通過篩選判定為True的情況降低了);
但是,相對的也付出代價,
就是更高的False Negative(同樣的,原本為True的樣本被誤判而過濾掉的情況提高了)。
除了誤判與門檻寬鬆對準確率造成的影響之外,
課程也談到訓練資料的廣度與兼容程度的重要性。
盡可能讓訓連集合兼顧或涵蓋到到實際應用時可能會遇到的所有情況。
舉例來說,
假如我們要辨識的對象是車子(Car),
訓練集最好又包含所有可能會遇到的測試情況,
包含卡車、遊覽車、廂型車、跑車、聯結車...等等,
而不要僅僅是房車與轎車(雖然是日常最容易見到的車種)。
為了兼顧準確率以及樣本的兼容程度(coverage and generalization),
準備一個大樣本的訓練集與正確的標記,
是建立一個實務上可靠的機器學習模型(ML Model)的基本要求與前提。


 iThome鐵人賽
iThome鐵人賽